
Kafka no Azure com Event Hubs

Neste artigo você vai entender como funciona o Kafka no Azure com Event Hubs — o serviço gerenciado da Microsoft que implementa o protocolo Kafka sem a necessidade de gerenciar brokers, ZooKeeper ou clusters. Kafka no Azure com Event Hubs é a escolha ideal para quem precisa de mensageria de alta performance em escala, com toda a infraestrutura gerenciada pela Microsoft. Ao longo desta série, você vai provisionar todos os recursos com Terraform e ver o código funcionando com Python e conectores Kafka.
- ⚙️ Art. 01 (este): Kafka no Azure com Event Hubs
- 🔒 Art. 02: Azure Event Hubs com Terraform
- 🔒 Art. 03: Python e Kafka no Azure Event Hubs
- 🔒 Art. 04: Kafka Connect no Azure Container Instances
- 🔒 Art. 05: Schema Registry no Azure Event Hubs
- 🔒 Art. 06: Monitoramento Kafka com Grafana no Azure
Sumário
- O que é Apache Kafka
- Kafka no Azure: por que Event Hubs
- Conceitos fundamentais: partições, consumer groups e retenção
- Arquitetura event-driven com Event Hubs
- Kafka self-hosted vs Azure Event Hubs
- Resource Group com Terraform
- Quando usar Kafka no Azure com Event Hubs
- Próximos passos da série
O que é Apache Kafka
Apache Kafka é uma plataforma distribuída de streaming de eventos criada pelo LinkedIn e depois doada para a Apache Software Foundation. Na prática, Kafka funciona como um log de eventos append-only e particionado, onde produtores publicam mensagens em tópicos e consumidores leem essas mensagens de forma independente, mantendo cada um seu próprio offset de leitura. Essa arquitetura descoupled — ou seja, produtores e consumidores são completamente independentes — é o que torna o Kafka tão poderoso para sistemas de alta escala e alto throughput.
Kafka resolve um problema clássico em sistemas distribuídos: como comunicar dezenas de microsserviços sem criar dependências diretas entre eles? Em vez de chamadas síncronas REST, os serviços publicam eventos em tópicos Kafka e outros serviços consomem esses eventos no seu próprio ritmo. Isso garante resiliência, pois se um consumidor cai, os eventos continuam no log e são processados quando o consumidor se recupera.
O Kafka tradicional — self-hosted — exige a gestão de brokers, ZooKeeper (ou KRaft nas versões mais recentes), armazenamento, particionamento e replicação. Em produção, isso representa uma complexidade operacional significativa. É aqui que entra o Kafka no Azure com Event Hubs: toda essa infraestrutura fica a cargo da Microsoft, e você usa o mesmo protocolo Kafka que já conhece.
Kafka no Azure: por que Event Hubs
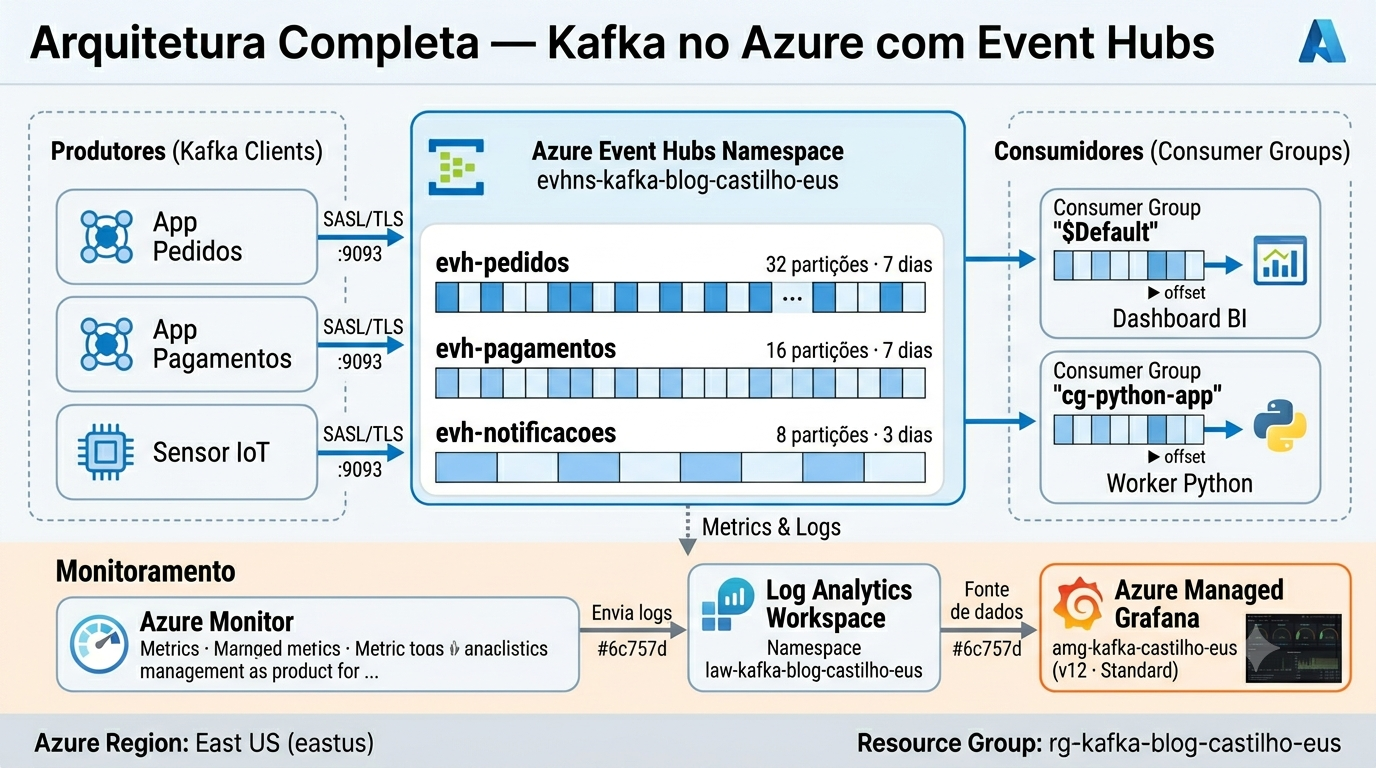
O Azure Event Hubs tem suporte nativo ao protocolo Apache Kafka desde 2018. Isso significa que você pode apontar qualquer cliente Kafka — seja em Python, Java, .NET ou Go — para um Event Hubs namespace sem alterar uma linha de código além das configurações de autenticação. O Kafka no Azure com Event Hubs expõe um endpoint compatível com o protocolo Kafka na porta 9093, usando SASL/SSL sobre TLS.
Tecnicamente, cada Event Hub dentro de um namespace é equivalente a um tópico Kafka. As partições funcionam da mesma forma — mensagens dentro de uma partição são ordenadas e processadas sequencialmente. Os consumer groups do Kafka mapeiam diretamente para os consumer groups do Event Hubs. A retenção de mensagens funciona da mesma forma, configurável por event hub.
A grande vantagem do Kafka no Azure com Event Hubs é o modelo SaaS: você paga por throughput units (ou processing units no SKU Premium) e escalabilidade automática, sem precisar provisionar VMs, configurar replicação ou fazer patch de brokers. Para equipes que já têm cargas de trabalho no Azure, Event Hubs se integra nativamente com Azure Functions, Stream Analytics, Data Factory, e o ecossistema Terraform da Microsoft.
Conceitos fundamentais: partições, consumer groups e retenção
Antes de provisionar o Kafka no Azure com Event Hubs com Terraform, é importante entender os três conceitos que determinam o throughput e o comportamento do seu sistema: partições, consumer groups e retenção de mensagens.
Partições
Partições são a unidade de paralelismo do Kafka. Um event hub com 32 partições pode ser consumido por até 32 consumidores em paralelo, cada um responsável por um subconjunto das mensagens. O número de partições é definido na criação do event hub e não pode ser reduzido depois — só aumentado no SKU Premium. No SKU Standard (que usamos nesta série), o número é fixo na criação. Para eventos de pedidos, onde a ordem importa por cliente, use a chave de partição para garantir que eventos do mesmo cliente caiam sempre na mesma partição.
Consumer Groups
Consumer groups permitem que múltiplas aplicações consumam o mesmo event hub de forma independente, cada uma mantendo seu próprio offset. Por exemplo, um event hub de pedidos pode ter um consumer group para o serviço de pagamento e outro para o serviço de notificações — os dois recebem todos os eventos, mas processam de forma independente. No SKU Standard do Azure Event Hubs, o limite padrão é 20 consumer groups por event hub.
Retenção
A retenção define por quantos dias as mensagens ficam disponíveis no event hub para leitura. No SKU Standard, o máximo é 7 dias. Isso é útil para replay de eventos — se um consumidor ficou offline por horas ou dias, ele pode reprocessar eventos a partir de qualquer offset dentro da janela de retenção. Para retenção maior, use o recurso Event Hubs Capture para arquivar eventos no Azure Storage ou Data Lake.
Arquitetura event-driven com Event Hubs
A arquitetura que vamos construir nesta série usando Kafka no Azure com Event Hubs simula um sistema de e-commerce com três event hubs: pedidos (32 partições, 7 dias), pagamentos (16 partições, 7 dias) e notificações (8 partições, 3 dias). Cada event hub tem throughput proporcional ao volume esperado de eventos.
No fluxo típico: o serviço de pedidos publica no event hub evh-pedidos, o serviço de pagamentos consome esse evento, processa e publica no evh-pagamentos, e o serviço de notificações consome ambos para enviar emails e push notifications. Todos esses serviços são desacoplados — se o serviço de notificações cair por 6 horas, os eventos ficam no log (dentro da janela de retenção) e são processados quando ele volta.
Com Kafka no Azure com Event Hubs e Terraform, toda essa topologia é versionada como código: namespace, event hubs, consumer groups, auth rules e schema groups são todos recursos Terraform que podem ser revisados em PR, replicados em ambientes diferentes e destruídos com um único comando.
Kafka self-hosted vs Azure Event Hubs
A decisão entre rodar Kafka self-hosted no Azure (via VMs ou AKS) e usar o Kafka no Azure com Event Hubs como serviço gerenciado depende principalmente de três fatores: controle, custo e complexidade operacional.
| Critério | Kafka self-hosted | Azure Event Hubs |
|---|---|---|
| Gestão de brokers | Manual — VMs, patches, reinícios | Gerenciado pela Microsoft |
| ZooKeeper / KRaft | Necessário configurar | Abstraído |
| Escalabilidade | Manual — adicionar brokers | Automática via Throughput Units |
| Compatibilidade Kafka | 100% nativa | Protocolo Kafka (porta 9093) |
| Retenção máxima (Standard) | Ilimitada (depende do disco) | 7 dias (Standard) / 90 dias (Premium) |
| Custo base (SKU Standard) | VMs + Storage + rede | Por throughput unit + eventos |
| Kafka Connect nativo | Sim | Via ACI / AKS (art. 04) |
| Schema Registry | Confluent Schema Registry | Event Hubs Schema Registry (art. 05) |
