1: Planejamento de DR Azure E Landing Zone
Implementar uma estratégia de SRE no Azure exige mais do que apenas ferramentas técnicas; exige uma mudança de mentalidade focada em confiabilidade e objetivos de negócio claros. Antes de configurar qualquer recurso, o Site Reliability Engineer deve definir as métricas que guiarão a resiliência do ambiente.
O que você vai aprender:
Fase 1: Planejamento e Requisitos de Negócio
O sucesso de uma jornada de SRE no Azure começa no “Porquê”. O papel do SRE é traduzir a necessidade da empresa em parâmetros técnicos que garantam a continuidade dos serviços mesmo em cenários de falha crítica.
“O SRE não evita apenas falhas; ele gerencia o risco para garantir que o sistema atenda às expectativas do usuário final.”
Definindo RTO e RPO: O Coração da Disponibilidade
Para uma arquitetura robusta de SRE no Azure, precisamos estabelecer dois pilares fundamentais de recuperação de desastres:
- RTO (Recovery Time Objective): É o tempo máximo aceitável para restaurar a aplicação após uma falha. Se o seu RTO for de 15 minutos, sua automação deve ser capaz de subir o ambiente nesse intervalo.
- RPO (Recovery Point Objective): Define a quantidade de dados que a empresa aceita perder. Por exemplo, um RPO de 5 minutos exige replicação constante de bancos de dados.
 Legenda: O equilíbrio entre RTO e RPO na arquitetura de nuvem.
Legenda: O equilíbrio entre RTO e RPO na arquitetura de nuvem.
Topologia: Definindo Região de Origem e Destino
A topologia é o desenho geográfico da sua resiliência. Ao aplicar práticas de SRE no Azure, é comum utilizarmos regiões emparelhadas (Paired Regions) para minimizar a latência e garantir conformidade de dados.
| Conceito | Exemplo Prático |
|---|---|
| Região de Origem | Brazil South (São Paulo) |
| Região de Destino | East US (Virgínia) ou South Central US |
Para aprofundar seus conhecimentos em infraestrutura escalável, recomendo consultar a documentação oficial do Azure Well-Architected Framework, que é a base para qualquer profissional que deseja dominar a cultura SRE.
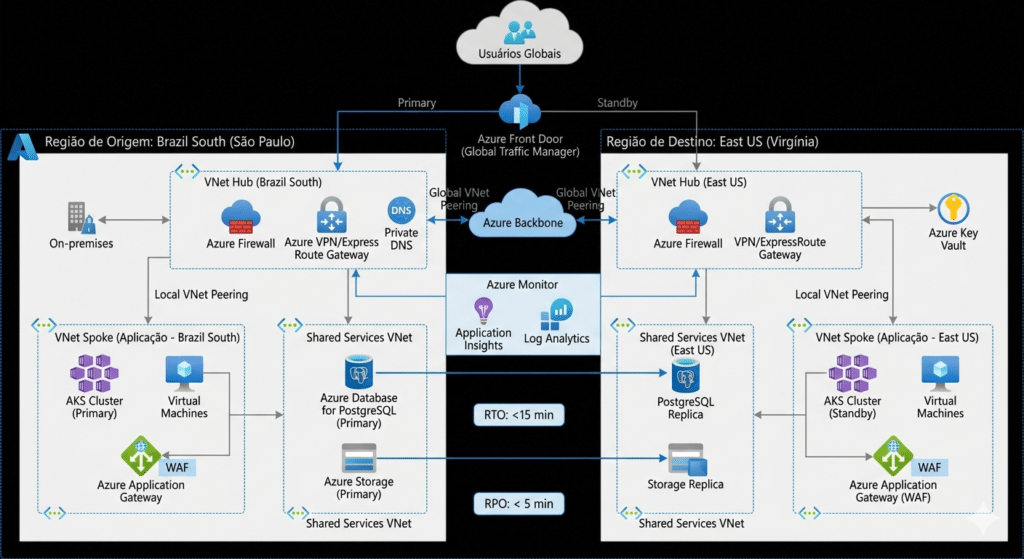
Arquitetura de Conectividade: Hub-and-Spoke Multi-Região
A base de uma topologia de rede resiliente para SRE no Azure reside na separação de responsabilidades e na redundância geográfica. Ao desenhar a rede, utilizamos o modelo Hub-and-Spoke para centralizar serviços compartilhados e isolar as aplicações.
Estrutura da Rede Geográfica
- VNet Hub (Região Primária – Brazil South): Contém o Azure Firewall, Gateway de VPN/ExpressRoute e serviços de DNS privado.
- VNet Spoke (Aplicação): Onde residem os workloads (AKS, VMs, App Services). Conectada ao Hub via VNet Peering.
- VNet Hub (Região Secundária – East US): Réplica da infraestrutura de rede para garantir que, em caso de desastre regional, o tráfego possa ser redirecionado instantaneamente.
Para garantir que o tráfego flua corretamente durante um failover, implementamos o Azure Front Door ou Traffic Manager. Essas ferramentas de nível global são essenciais em qualquer estratégia de SRE no Azure, pois monitoram a saúde dos endpoints e realizam o desvio de tráfego (failover) de forma automática baseado no RTO definido.
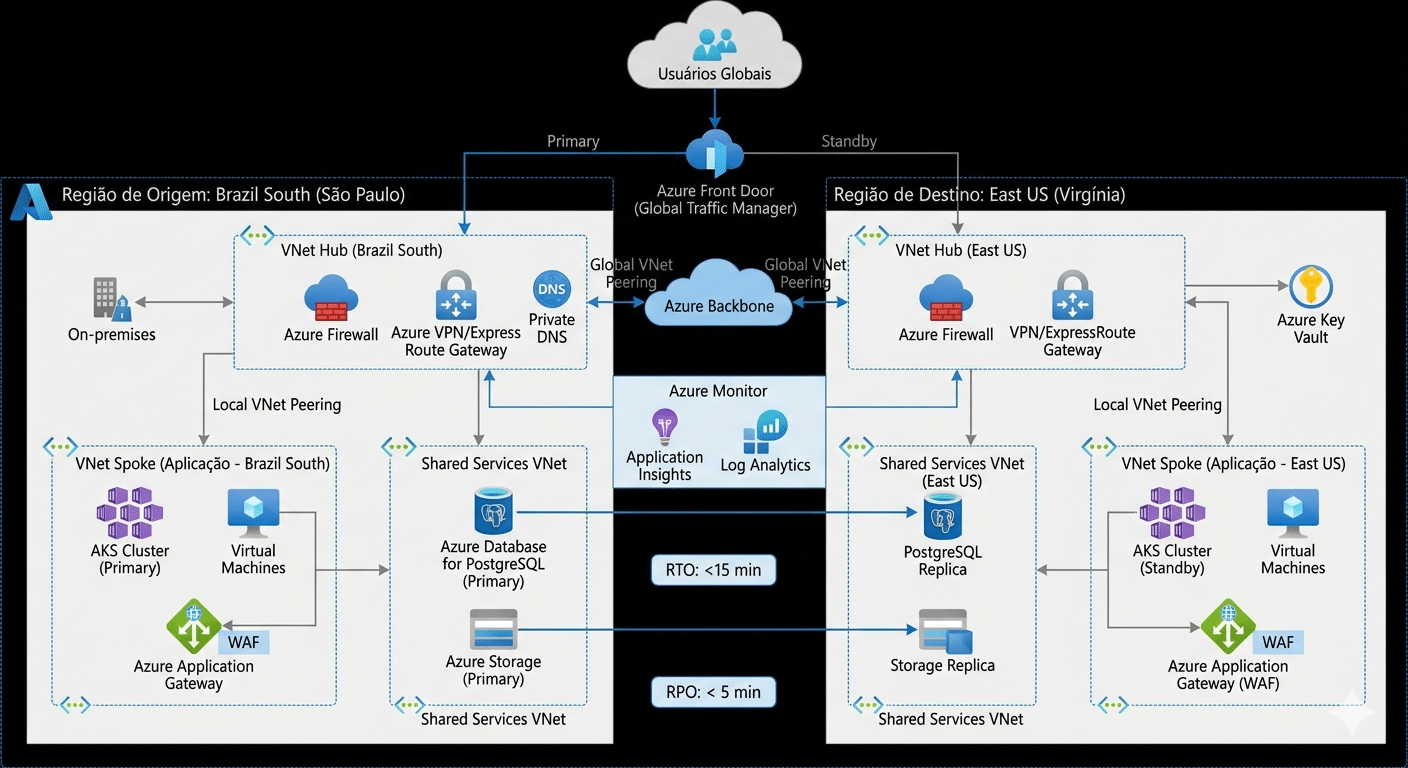
Segurança e Inspeção de Tráfego
Não basta estar conectado; a rede precisa ser segura. A topologia deve incluir:
- Network Security Groups (NSGs): Filtragem de tráfego ao nível de sub-rede.
- Azure Bastion: Acesso administrativo seguro sem exposição de IPs públicos.
- Global VNet Peering: Para conectar as redes de São Paulo e Virgínia através do backbone da Microsoft, reduzindo a latência.
Dica de SRE: Utilize Infraestrutura como Código (Terraform ou Bicep) para garantir que a topologia na região de destino seja uma cópia idêntica da origem. A consistência ambiental é vital para a confiabilidade.
Ao estruturar seu ambiente com essas premissas, você garante que a operação seja previsível, mensurável e, acima de tudo, confiável para o negócio.
Interessado em saber mais sobre artigos relacionados ao Microsoft Azure CLIQUE AQUI
🚀 Vamos nos conectar?
Não perca nenhuma oportunidade! Cadastre-se nas minhas redes e no canal do YouTube para receber conteúdos de TI, Cloud, Azure, Kubernetes e DevOps em primeira mão.
Dica: No Facebook, todos os artigos do blog são publicados automaticamente. Vale a pena curtir!
💬 Dúvidas ou Problemas?
Com o intuito de ajudar a comunidade, caso você tenha dúvidas ou encontre problemas na execução dos comandos deste artigo, deixe um comentário abaixo. Responderei o mais breve possível!
Muito obrigado pela visita e até o próximo post!
Jefferson Castilho
Especialista em Cloud & DevOps.
Este guia técnico é exclusivo do Blog do Castilho. Explore nossa para mais conteúdos sobre IA e Cloud.
